profile工具
写完几万代码,在测试环境跑的好好的,一上线就发现只有几十QPS/TPS,如何快速定位性能瓶颈; 抑或是发生有内存泄漏的问题,如何在这庞杂的代码库中找到泄漏的“凶手”代码;
profile工具就是golang作者给Goer提供的定位以上棘手问题的利器
核心原理是:通过「采样」瓶颈现场时的程序运行时数据,生成可视化图形,让我们更好的观察出服务器的CPU/内存被哪些方法消耗,进而快速缩小问题排查范围
通过本文,可以基本了解profile工具的使用
怎么使用
2.1、程序中预留后门
在程序的main.go中,导入pprof包
1
import _ "net/http/pprof"
添加profile router映射,copy就行
1
2
3
4
5
r.HandleFunc("/debug/pprof/", pprof.Index)
r.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
r.HandleFunc("/debug/pprof/profile", pprof.Profile)
r.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
r.HandleFunc("/debug/pprof/trace", pprof.Trace)
可以为pprof专门留一个单独的端口,用于采样时使用,也可以跟http协议共用一个端口
2.2、采样
采样cpu信息
1
go tool pprof -http=0.0.0.0:8080 http://{server_ip}:{profile_port}/debug/pprof/profile?seconds=10
采样内存信息
1
go tool pprof -http=0.0.0.0:8080 http://{server_ip}:{profile_port}/debug/pprof/heap?seconds=10
其中seconds参数表示采样的时长,应该越长数据越准备,实践中一般30秒以内即可,go tool pprof 工具运行后,会在本地起一个进程,监听8080端口
我们可以在浏览器中通过http://localhost:8080/ui打开可视化的界面,一般是通过Graph及Flame Graph两种图形来观察程序消耗的CPU及内存
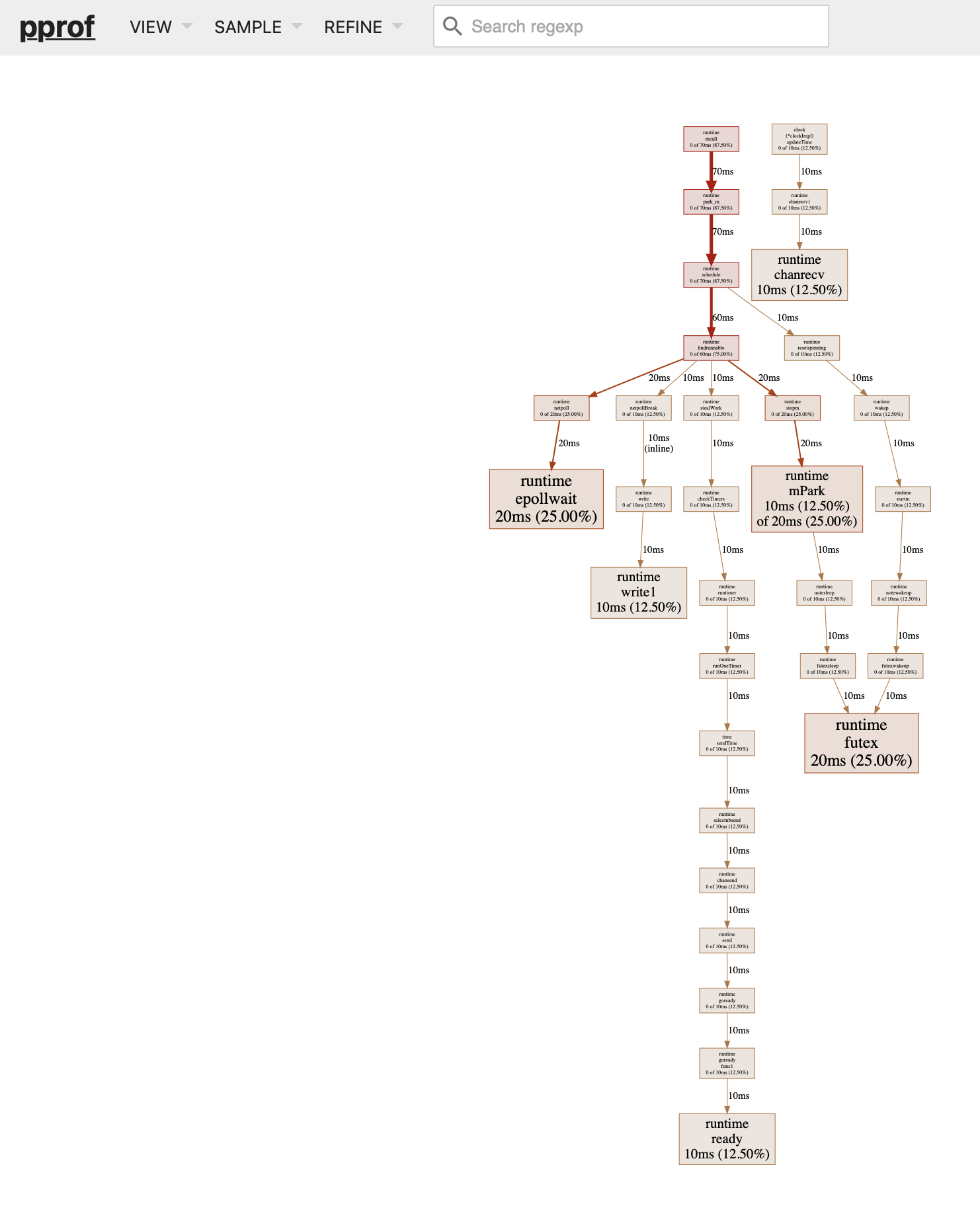
Graph中线条代表调用方向,粗细代表耗时大小;实线表示直接调用,虚线表示跳过了中间一些不关键的方法
方框代表具体的方法名,方法耗时越多,方框颜色越红越大,具体的说明参考 profile图形解读
Flame Graph也就是「火焰图」,通过楼层表示调用关系,楼层越高,表示调用链越长;每一层通过长度表示耗时大小,越长耗时越大

2.3、分析
有些系统底层方法虽然方框比较大但应当排除掉,比如runtime.Syscall;
对于性能分析我们应该重点关注以下几类方法
1、我们自己写的方法,尤其是新增的方法
这是要重点排查的,99.99%都是我们使用姿势有问题,对语言的理解不到位
有些年经的同学,一上来就轻易排除掉自己写的代码的嫌疑,然后重点怀疑是不是框架的问题,第三库的问题,甚至系统的问题
方向一但错了,结果就很可能“南辕北辙”,不能从代码山中快速定位到原因
2、反射
反射也是性能消耗的常见原因,尽量用在非核心场景;或者能否用接口方式替换掉
3、序列化/反序列化
一般如果是框架层调用的话,是正常的消耗;但是如果是业务层调用量比较高,应该排查下是否使用合理及必要;
比如结构体中字段是指针类型,如果直接打印,看到的是指针地址,不利于分析问题,很多同学就喜欢直接把整个结构体json.Marsha(obj)打印出来,对于这种场景如果是核心路径,建议排查完问题及时去掉这种代码;
4、正则表达式
类似这种字符串的O(n^2) 级别的操作,在核心场景都应该尽量避免,还有正则有无开启预编译
另外类似字符串匹配的需求,可以考虑Trie树数据结构能否解决
5、日志打印
过多的日志打印,也会消耗cpu,一来是 format模板解析 也是对字符串的复杂解析操作;
二来是日志刷的太快,io的读写底层都是系统调用,也会让进程频繁的在用户态/系统态切换,让程序的性能下降
我们尽量关闭一些非必要日志,“合理聪明”的打印日志
关于日志的打印也是一门经验学,这里可以好好谈谈,后续再补充一篇谈谈我的一些经验
总结
使用profile定位性能问题还是比较简单直接的,但是前提是要在故障发生的时刻能采样到数据
这个在实际操作中还是有些困难的,比如故障发生在“凌晨”,等你第二天上班看到告警的时候,进程早已经重启了,甚至机器都被重启了
又或者故障一发生现场就没了,之前我有遇到过内存泄漏是瞬间发生,然后服务端进程又是部署在k8s的Pod中,导致在发生内存泄漏时,Pod已经被集群kill掉,导致无法及时去现场定位;
所以我们还是需要一个进程的尸体数据(coredump),哪怕进程已经被kill,我们还是可以对尸体分析出一些有用的信息