什么是 unsafe包
Go是强类型语言,可以在编译期就发现类型转换的错误,这可以大大降低我们代码出错误的概率;
在有些对性能要求较高的场景,比如string与[]byte之间的转换,使用常规的方式性能一般,如果使用unsafe的能力,可以做到零复制,性能大大提高
贴个数据感觉下:
1
2
3
4
5
6
7
8
9
10
strslice gotip test -benchmem -bench .
goos: darwin
goarch: arm64
pkg: github.com/smallnest/study/strslice
BenchmarkString2Slice-8 18826 63942 ns/op 1048579 B/op 1 allocs/op
BenchmarkString2SliceReflect-8 1000000000 0.6498 ns/op 0 B/op 0 allocs/op
BenchmarkString2SliceUnsafe-8 1000000000 0.8178 ns/op 0 B/op 0 allocs/op
BenchmarkSlice2String-8 18686 65864 ns/op 1048580 B/op 1 allocs/op
BenchmarkSlice2StringReflect-8 1000000000 0.6488 ns/op 0 B/op 0 allocs/op
BenchmarkSlice2StringUnsafe-8 1000000000 0.9744 ns/op 0 B/op 0 allocs/op
使用unsafe包可以绕过Go中的类型系统,完成一些骇客式的性能优化;
Go源码中很多对性能要求高的地方都使用了unsafe包,我们学习unsafe包也并不是为了去做一些骇客行为,对于我们方便阅读Go源码也是有帮助的
1、unsafe包说明
unsafe包下只定义了一个类型以及5个方法(到go1.18版本),另外两个类型只是unsafe文档中使用
1
2
3
4
5
6
7
8
9
10
11
12
13
type ArbitraryType int // 任意类型,只是为了unsafe文档说明使用,实际并未使用
type IntegerType int // Interger类型,同上
type Pointer *ArbitraryType // 任意指针
func Sizeof(x ArbitraryType) uintptr
func Offsetof(x ArbitraryType) uintptr
func Alignof(x ArbitraryType) uintptr
func Add(ptr Pointer, len IntegerType) Pointer
func Slice(ptr *ArbitraryType, len IntegerType) []ArbitraryType
Go的类型系统加上unsafe包下定义的类型,构成了以下四类对象
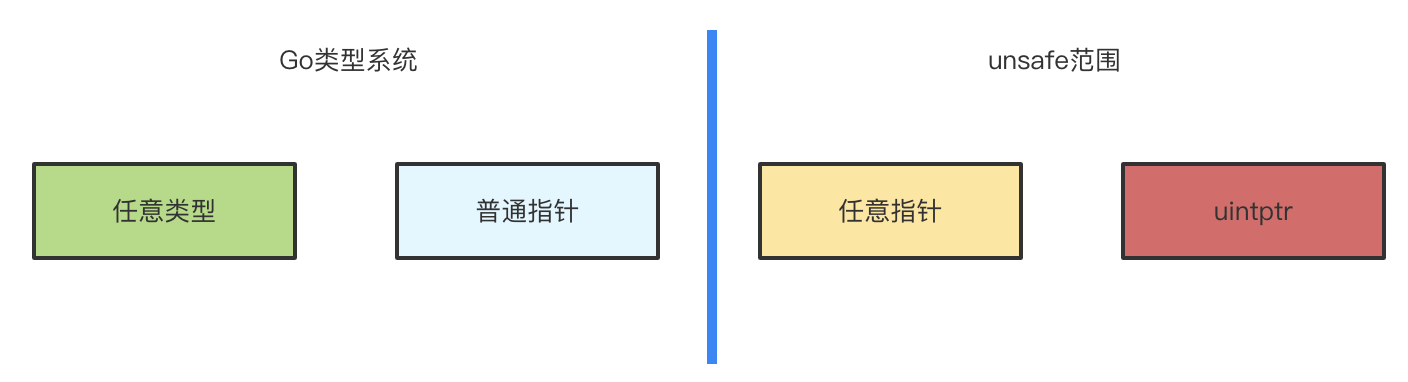
为什么在常规的类型系统之外增加Pointer及uintptr两种类型呢?
在常规手段下,我们只能对任意类型进行读写,普通指针只读,以及任意类型与普通指针之间的转换这三类操作
而借助Pointer可以在不同类型的普通指针之间进行转换(当然是有前提的,后面会具体说明)
但是Pointer不能对指针进行类似C/C++的地址偏移操作,使用uintper配合Add/Offsetof等方法就可以对内存地址进行偏移操作,进而实现直接修改内存数据的目的,比如修改struct中私有字段值的能力
普通指针与Pointer值的含义是指向对象的地址,而uintper值就是对象的内存的地址,是个整数,所以可以进行算术运算;
这里要特别强调一点:uintper并不被Go认为是活引用,所以uintper引用的地址可能会在操作之前变化,所产生的Bug是非常微妙且难以发现
这四类对象是可以相互转换的,unsafe中定义了如下规则
- A pointer value of any type can be converted to a Pointer.
- A Pointer can be converted to a pointer value of any type.
- A uintptr can be converted to a Pointer.
- A Pointer can be converted to a uintptr.
具体类型之间转换方式如下:

unsafe包实战
1、类型之间的转换
我们在Go类型系统下,无法把类型A转成类型B,而unsafe.Pointer就是一个桥梁
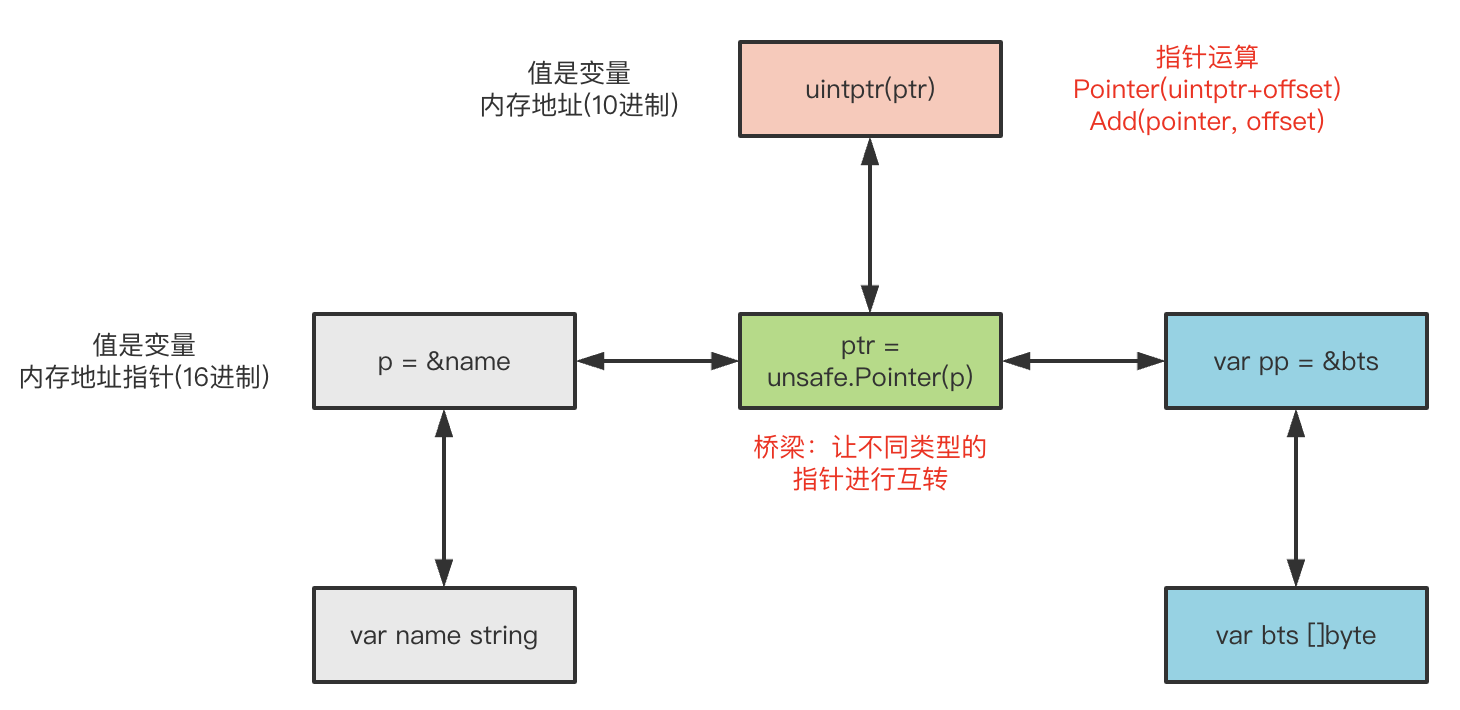
1
2
3
4
var f1 = Foo1{Val: 18, Text: "xxoo"}
var ptr1 = unsafe.Pointer(&f1)
var p2 = (*Foo2)(ptr1) // 把 Foo1 -> Foo2
fmt.Printf("get value2 from ptr1:%+v\n", int32(p2.Value)) // 18
这里的转换是有前提的:
T2 T1 内存布局相同或T2内存布局小于T1, 则T1可以安全转换为T2;反之则不安全
原文:
Provided that T2 is no larger than T1 and that the two share an equivalent memory layout, this conversion allows reinterpreting data of one type as data of another type.
什么叫内存布局,简单来讲就是结构体定义的字段类型(字段长度)+顺序要相同,名字可以不同;
什么叫小于,比如都是int类型,T1的字段是int64, T2的对应字段是int32,T3的对应字段是int16,那么T3 < T2 < T1;
当T1往T2转时候,只要字段的值没有超过int32的范围,就能正确转换,所以是安全的
当T2往T1转时候,高位会被填充,导致数据错误(可通过类型转换恢复),所以是不安全的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
type Foo1 struct {
Val int32
Text string
}
type Foo2 struct {
name string
value int32
age int32
}
type Foo3 struct {
value int32
name string
age int32
}
比如以上3个结构体定义,Foo3与Foo1就算布局相同,并且Foo3 > Foo1;
Foo3可以转换成Foo1并且是安全的,虽然两者字段的名称不相同,甚至大小写都不同;
反过来Foo1转成Foo3也可以,但是age字段就是没值,这就是不安全
而Foo1与Foo2就算布局不同,虽然Foo2与Foo3只是字段顺序不同
强制转换会产生panic: runtime error: invalid memory address or nil pointer dereference错误
从这一点也可以理解为什么叫不安全这个名字了,虽然当前Foo3与Foo1的布局是相同的,现在代码能work; 但是如果哪一天Foo3中字段顺序调整了一下变成Foo2, 代码又不能work; 代码能不能工作竟然强依赖字段书写的顺序
这里最经典最实用的case是string与[]byte之间的互转, 使用unsafe可以减少内存分配
常见的实现有以下几种
1
2
3
4
5
6
7
8
// toBytes performs unholy acts to avoid allocations
func toBytes(s string) []byte {
return *(*[]byte)(unsafe.Pointer(&s)) // cap == 0
}
// toString performs unholy acts to avoid allocations
func toString(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
上面代码出自 Kubernates
需要说明的是,上面的toBytes执行后的[]byte有点瑕疵,cap([]byte)==0,更好的实现是下面这种
1
2
3
4
5
6
7
8
func SliceByteToString(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
func StringToSliceByte(s string) []byte {
x := (*[2]uintptr)(unsafe.Pointer(&s))
h := [3]uintptr{x[0], x[1], x[1]} // data, len, cap
return *(*[]byte)(unsafe.Pointer(&h))
}
为什么string能与[]byte类型之间互换,string类型的真正结构定义如下:
1
2
3
4
5
// string真正类型定义
type stringStruct struct {
str unsafe.Pointer
len int
}
而[]byte是slice类型,其结构定义如下:
1
2
3
4
5
6
// []byte, slice真正类型定义
type slice struct {
array unsafe.Pointer
len int
cap int
}
从上可以看出string与[]byte的内存布局是相同的,[]byte比string多了个cap字段, 所以[]byte > string的
这才是string与[]byte能互转的基础
也就知道了Kubenates的实现为什么不好,因为是从小往大转,会丢失cap信息
1
2
3
func toBytes(s string) []byte {
return *(*[]byte)(unsafe.Pointer(&s)) // 实际上只能覆盖array, len,没有cap
}
另外下面这个代码也很值得学习研究,string的底层是struct, 然后转成了*[2]uintptr类型,
这是个数组,然后再构造[3]uintptr类型的h,再把h转为slice,最终获取了正确的[]byte数据
1
2
3
4
5
func StringToSliceByte(s string) []byte {
x := (*[2]uintptr)(unsafe.Pointer(&s)) // str, len
h := [3]uintptr{x[0], x[1], x[1]} // array, len, cap
return *(*[]byte)(unsafe.Pointer(&h))
}
这段代码也揭示了struct与array之间的界限其实没那么彻底,都是内存中连续的空间,
只是array/slice中每个元素的类型都是相同/大小的,而struct每个字段的类型不一定相同/大小; 但是可以在uintptr层面摸平这个差异,借助 []uinptr来实现不同struct之间的互转
我们来尝试下把Foo3转为Foo4,两者在memory layout层面并不相同
1
2
3
4
5
6
7
var f3 = Foo3{value: 100, name: "mingo", age: 33}
ptr3 := unsafe.Pointer(&f3)
x := (*[4]uintptr)(ptr3) // int32, uintptr, int, int32
z := [4]uintptr{x[1], x[2], x[0], x[3]} // uintptr, int, int32, int32
f4 := (*Foo4)(unsafe.Pointer(&z))
fmt.Printf("%+v \n", *f4) // {name:mingo value:100 age:74569000}
可以看到name, value字段是成功复值了,但是age字段不是期望的33,
这里牵扯到内存对齐层面的问题,不是本文的重点,这里先留个坑,在之后的文章里再详细说明
这里的bugfix方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 方法一:修改Foo4的定义,确保对齐
type Foo4 struct {
name string // 16
value int16 // 4
_ int32 // 用于pending填充
age int32 // 4
}
// 方法二:不改Foo4,改复制手段
z := [4]uintptr{x[1], x[2], x[0], x[3]} // str, len, int32, int32
f4 := (*Foo4)(unsafe.Pointer(&z))
// x[0]是int32,内存对齐导致后面有pending4个字节,然后x[3]值就被填充
f4.age = *(*int32)(unsafe.Pointer(&x[3]))
fmt.Printf("%+v \n", *f4)
另外的case有Go标准库中string的复制,Float64与uint64互转的操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
func Clone(s string) string {
if len(s) == 0 {
return ""
}
b := make([]byte, len(s))
copy(b, s)
return *(*string)(unsafe.Pointer(&b)) // []byte -> string
}
func Float64bits(f float64) uint64 {
return *(*uint64)(unsafe.Pointer(&f))
}
func Float64frombits(b uint64) float64 {
return *(*float64)(unsafe.Pointer(&b))
}
2、对指针进行偏移操作
通常实现指针地址偏移2种方式:
- unsafe.Pointer(
uintptr+ offset) - unsafe.Add(ptr, len) // 对结构体的字段遍历修改比较方便
修改结构体中未导出变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
type Foo3 struct {
value int32
name string
age int32
}
// 该代码没有任何意义,只是为了说明uintptr能力而强行编写
// 实际中遇到类似需求的概率极低,即便遇到也有其它方式解决
func TestModifyUnExportField(t *testing.T) {
var f3 = Foo3{}
ptr := unsafe.Pointer(&f3)
pName := (*string)(unsafe.Add(ptr, unsafe.Offsetof(f3.name)))
*pName = "mingochen" // f3.name = "mingochen"
age := (*int32)(unsafe.Add(ptr, unsafe.Offsetof(f3.age)))
*age = 18 // f3.age = 18
ptrVal := unsafe.Pointer(uintptr(ptr) + unsafe.Offsetof(f3.value))
*(*int32)(ptrVal) = 100 // f3.value = 100
fmt.Printf("foo:%+v \n", f3) // foo:{value:100 name:mingochen age:18}
}
在Go中对指针进行偏移要十分小心,不要越界,否则程序会panic
1
2
3
4
5
6
7
// INVALID: 字符串长度越界
var s thing
end = unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + unsafe.Sizeof(s))
// INVALID: 数组越界
b := make([]byte, n)
end = unsafe.Pointer(uintptr(unsafe.Pointer(&b[0])) + uintptr(n))
另外,unsafe文档里提到,对uintpr值不要使用临时变量保存,而是尽量在一个表达式中完成;
是为了防止uintptr指向的地址被回收分配给其它对象,进而读/写错误;
// 这里我有点不理解,代码写一行也不代表是原子操作,等我搞懂后再填坑这里
1
2
3
4
// INVALID: uintptr cannot be stored in variable before conversion back to Pointer.
// 在这2行代码执行之间,可能u指向的对象地址被回收分配给另一个对象
u := uintptr(p)
p = unsafe.Pointer(u + offset)
不能对空指针进行偏移
1
2
3
// INVALID: conversion of nil pointer
u := unsafe.Pointer(nil)
p := unsafe.Pointer(uintptr(u) + offset)
系统调用
1
syscall.Syscall(SYS_READ, uintptr(fd), uintptr(unsafe.Pointer(p)), uintptr(n))
跟反射的配合
1
p := (*int)(unsafe.Pointer(reflect.ValueOf(new(int)).Pointer()))
1
2
3
4
var s string
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // case 1
hdr.Data = uintptr(unsafe.Pointer(p)) // case 6 (this case)
hdr.Len = n
3、其它API使用说明
上面介绍了Add,Offsetof方法的使用,下面完整的讲下
Add
对指针进行偏移,可以参见上面的demo
Offsetof
获取结构体指定字段相对于结构体头的偏移位置,可以参见上面修改结构体私有字段的demo
Sizeof
获取一个类型的字面大小,不包含实际引用的数据大小
1
2
3
4
5
6
7
var name = "mingochen"
//type stringStruct struct {
// str unsafe.Pointer // 8
// len int // 8
//}
var n = unsafe.Sizeof(name) // 16
name的底层结构是 Pointer, int,所以总大小就是8+8=16;而无论str字段中包含多少个字符
Alignof
用于计算该类型需要内在对齐的字节数
size(v) % max_align == 0
1<= max_align <= 8
Slice
用于数组元素复制的另一方法
1
2
3
4
5
var names = []string{"tx", "ali", "jd", "baidu"}
cpNames := unsafe.Slice(&names[1], 2)
fmt.Printf("val:%+v, len:%+v, cap:%+v \n", cpNames, len(cpNames), cap(cpNames))
//output: val:[ali jd], len:2, cap:2
总结
unsafe包通过Pointer来实现不同类型之间对象的转换,主要是为了底层数据的共享,减少内存分配,提升性能;
能转换成功的前提是两者之间的内存布局要相同或从大转到小
unsafe包通过uintptr来实现对指针的偏移操作,进而直接访问内存数据;
也有限制,不能越界,不能对nil进行偏移,不要保存到临时变量
以上两种方式都是绕过了Go类型系统,实现了常规手段达不到的优化效果
不过在使用unsafe包的过程中对代码写法要求较高,对要操作的数据结构十分熟悉,极易出bug,需要大量练习;
另外代码可读性,可维护性,平台移值性都不太好,建议少用或不用